Gemini API Pricing Comparatif : Quel Modèle Choisir en 2026 ?
Décortiquons le prix de l'API Gemini en 2026. Comparatif détaillé des modèles, des coûts par token et des fonctionnalités pour optimiser votre budget IA.
14 min de lecture
Alors que l'intelligence artificielle générative continue de redéfinir les possibilités technologiques, le choix de la bonne API est crucial pour le succès de vos projets. Google Gemini, avec sa gamme de modèles puissants, se positionne comme un acteur majeur. Mais comment naviguer dans son paysage tarifaire complexe ? En ce mois d'avril 2026, StackRev vous propose un comparatif approfondi du gemini api pricing, afin de vous aider à faire le choix le plus judicieux pour votre budget et vos besoins.
L'écosystème Gemini évolue rapidement. Les modèles se perfectionnent, les fonctionnalités s'enrichissent, et les structures tarifaires s'adaptent. Comprendre ces nuances est essentiel pour maîtriser vos coûts et maximiser la valeur de votre investissement en IA. Ce guide est conçu pour vous éclairer, en décortiquant chaque aspect du pricing de l'API Gemini, des modèles les plus économiques aux solutions d'entreprise les plus avancées.
Comprendre le Modèle Tarifaire de Gemini API
Avant de plonger dans les comparatifs spécifiques, il est important de saisir les fondamentaux du modèle tarifaire de Gemini API. Google facture généralement l'utilisation de ses modèles d'IA générative sur la base de la quantité de texte traitée, mesurée en tokens. Un token peut être un mot, une partie de mot, ou un caractère, selon la langue et le modèle.
Les deux métriques principales pour le calcul des coûts sont :
- Coût par 1 million de tokens d'entrée (Input) : Ce tarif s'applique aux données que vous envoyez au modèle pour traitement (prompts, documents, images converties en texte, etc.).
- Coût par 1 million de tokens de sortie (Output) : Ce tarif concerne les données générées par le modèle en réponse à vos requêtes.
Il est crucial de noter que ces coûts peuvent varier considérablement en fonction du modèle Gemini choisi, de la taille de la fenêtre de contexte utilisée, et de l'activation de fonctionnalités supplémentaires comme le cache de contexte.
Les Différents Modèles Gemini et Leurs Tarifs
Google propose une gamme variée de modèles Gemini, chacun optimisé pour des cas d'usage et des budgets différents. Analysons leurs structures tarifaires en détail.
Gemini Flash Lite : L'Option Budget pour les Hauts Volumes
Le modèle Gemini Flash Lite se positionne comme la solution la plus abordable pour les développeurs et les entreprises qui gèrent un volume très important de requêtes.
Avec un coût d'entrée de seulement $0.10 par million de tokens et un coût de sortie de $0.40 par million, ce modèle est imbattable pour les applications nécessitant un traitement massif de données où le coût par unité est primordial. Sa fenêtre de contexte de 1 million de tokens offre une capacité de traitement conséquente.
Gemini 2.5 Flash : L'Équilibre Standard
Le Gemini 2.5 Flash offre un excellent équilibre entre performance et coût, le rendant idéal pour une large gamme d'applications de petite à moyenne taille.
Bien que légèrement plus cher que le Flash Lite, le Gemini 2.5 Flash propose une tarification plus compétitive sur les sorties et introduit la possibilité de cache de contexte, une fonctionnalité clé pour optimiser les coûts sur les requêtes répétitives.
Gemini 3 Flash (Preview) : Performance Équilibrée pour la Production
Le modèle Gemini 3 Flash Preview est conçu pour les charges de travail de production qui exigent un équilibre entre performance et coût.
Ce modèle se situe dans la catégorie "Standard" et offre des performances améliorées par rapport aux modèles Flash précédents. Le coût du cache de contexte est légèrement plus élevé, reflétant potentiellement des capacités accrues. Il est important de noter que les modèles en preview peuvent voir leurs tarifs ajustés avant leur disponibilité générale.
Gemini 2.5 Pro : La Puissance Professionnelle à Prix Compétitif
Pour les applications qui nécessitent des performances quasi-haut de gamme sans le coût le plus élevé, le Gemini 2.5 Pro est une option de choix.
Ce modèle se distingue par sa fenêtre de contexte étendue à 2 millions de tokens. Cependant, il introduit une tarification différenciée : le prix des tokens d'entrée et de sortie double lorsque la fenêtre de contexte dépasse 200 000 tokens. Le cache de contexte est également disponible à un tarif compétitif.
Gemini 3.1 Pro (Preview) : L'Avant-Garde Multimodale
Le Gemini 3.1 Pro Preview représente le summum des capacités multimodales de Google, offrant des fonctionnalités avancées pour les charges de travail d'entreprise.
Ce modèle est le plus coûteux, mais il offre des capacités de raisonnement améliorées et une prise en charge native de la génération d'images, ainsi que des entrées texte, image, vidéo et audio. La tarification est également différenciée pour les contextes dépassant 200K tokens, et le cache de contexte est plus cher, reflétant la complexité et la puissance du modèle. Il est important de noter que le Gemini 3.1 Pro a remplacé le Gemini 3 Pro Preview en mars 2026.
Comparatif des Fonctionnalités Clés
Au-delà du prix brut, les fonctionnalités offertes par chaque modèle peuvent influencer votre décision. La fenêtre de contexte et le cache de contexte sont particulièrement importants pour la gestion des coûts.
Fenêtre de Contexte : La Capacité de Mémoire du Modèle
La fenêtre de contexte détermine la quantité d'informations qu'un modèle peut prendre en compte simultanément lors d'une requête. Une fenêtre plus grande permet des interactions plus complexes et une meilleure compréhension du contexte.
| Feature | Fenêtre de Contexte |
|---|---|
| Gemini Flash Lite | 1M tokens |
| Gemini 2.5 Flash | 1M tokens |
| Gemini 3 Flash (Preview) | Non spécifiée |
| Gemini 2.5 Pro | 2M tokens |
| Gemini 3.1 Pro (Preview) | 1M tokens |
Le Gemini 2.5 Pro se démarque avec sa fenêtre de contexte de 2 millions de tokens, offrant une flexibilité inégalée pour les cas d'usage nécessitant une compréhension approfondie de longs documents ou de conversations étendues.
Cache de Contexte : Optimiser les Coûts sur les Requêtes Répétitives
Le cache de contexte permet de stocker des informations traitées précédemment, réduisant ainsi la nécessité de ré-envoyer les mêmes données à chaque requête. Cela peut entraîner des économies substantielles, allant jusqu'à 90% dans certains scénarios.
| Feature | Cache de Contexte |
|---|---|
| Gemini Flash Lite | Non disponible |
| Gemini 2.5 Flash | $0.03 / 1M tokens mis en cache |
| Gemini 3 Flash (Preview) | $0.05-$0.10 + $1/heure |
| Gemini 2.5 Pro | $0.125 / 1M tokens mis en cache |
| Gemini 3.1 Pro (Preview) | $0.20-$0.40 + $4.50/heure |
La disponibilité et le coût du cache de contexte varient. Le Gemini Flash Lite n'en dispose pas, tandis que les modèles Pro offrent des tarifs plus élevés mais potentiellement plus efficaces pour des charges de travail complexes.
Traitement par Lots et Capacités Multimodales
D'autres fonctionnalités importantes incluent le traitement par lots et le support multimodal.
- Traitement par Lots : Tous les modèles Gemini offrent une réduction de 50% sur les requêtes traitées par lots, une excellente nouvelle pour les applications qui peuvent regrouper des requêtes similaires.
- Capacités Multimodales : Les modèles les plus récents, comme le Gemini 3.1 Pro Preview et le Gemini 3 Flash Preview, prennent en charge nativement les entrées texte, image, vidéo et audio, et peuvent même générer des images. Le Gemini 2.5 Pro et le Gemini 2.5 Flash prennent également en charge les entrées multimodales, mais sans la génération d'images native.
Plans Consommateurs : L'Accès pour Tous
Au-delà de l'API pour les développeurs, Google propose également des plans consommateurs pour accéder aux modèles Gemini :
Ces plans sont parfaits pour les utilisateurs individuels ou les petites équipes souhaitant expérimenter les capacités de Gemini sans avoir à gérer une intégration API complexe.
Avantages et Inconvénients Généraux de Gemini API
Comme toute technologie, Gemini API présente ses forces et ses faiblesses.
Il est essentiel de prendre en compte la dépréciation de Gemini 2.0 Flash et de planifier la migration vers des alternatives plus récentes. La tarification différenciée pour les grandes fenêtres de contexte sur les modèles Pro est également un point à surveiller attentivement.
Les Changements Récents et à Venir
Le paysage de Gemini API est dynamique. Les mises à jour récentes et les prévisions pour l'avenir sont cruciales pour une planification à long terme.
- Mars 2026 : Le Gemini 3.1 Pro a remplacé le Gemini 3 Pro Preview, avec une tarification de $2.00/$12.00 par 1M de tokens pour le contexte standard.
- 1er Juin 2026 : Le Gemini 2.0 Flash sera arrêté. Les utilisateurs devront migrer vers le Gemini 2.5 Flash-Lite.
- T2 2026 : La tarification stable en disponibilité générale (GA) pour le Gemini 3.1 Pro est attendue, avec des estimations suggérant des prix autour de $1.50/$10 par 1M de tokens, en tenant compte des remises sur le cache de contexte et le traitement par lots.
- Outils de Contrôle des Coûts : Google a introduit de nouvelles fonctionnalités dans Google AI Studio permettant aux développeurs de définir des plafonds de dépenses mensuels et d'ajuster leur utilisation via des paliers.
FAQ : Vos Questions sur le Pricing Gemini API
Pour clarifier davantage les points clés, voici une section dédiée aux questions fréquemment posées.
Frequently Asked Questions
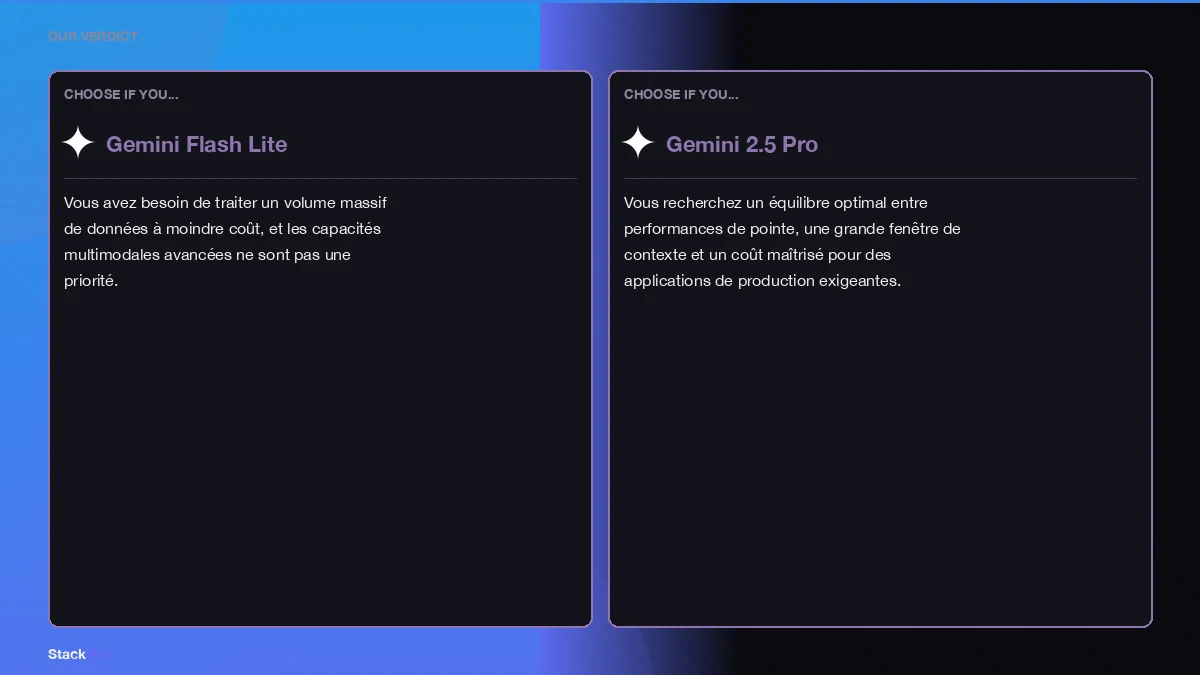
Verdict : Quel Modèle Gemini Choisir en 2026 ?
Le choix du modèle Gemini API le plus adapté dépendra de vos priorités : coût, performance, fenêtre de contexte, ou capacités multimodales.
Pour les projets personnels ou les applications à très haut volume où le coût par token est le facteur déterminant, le Gemini Flash Lite est le choix évident. Sa tarification imbattable en fait la solution idéale pour maximiser l'efficacité sans grever le budget.
Cependant, pour la plupart des charges de travail de production qui exigent une combinaison de puissance, de flexibilité et de coût raisonnable, le Gemini 2.5 Pro se révèle être le champion. Sa fenêtre de contexte de 2 millions de tokens, ses capacités multimodales et son prix compétitif pour des performances quasi-haut de gamme en font un investissement stratégique pour l'avenir.
N'oubliez pas de surveiller les annonces de Google concernant la disponibilité générale des modèles en preview et l'évolution des tarifs, notamment la stabilisation attendue pour le Gemini 3.1 Pro au T2 2026. En utilisant judicieusement les outils de contrôle des coûts et en comprenant les spécificités de chaque modèle, vous pouvez exploiter tout le potentiel de Gemini API pour vos innovations.